private void getNextval(StringList T, int[] nextval) {
int i, j; //代表第几个字符
i = 1;
j = 0;
nextval[1] = 0;
for (i=2; i < nextval.Length; i++)
{
while (j > 0 && T[i] != T[j + 1])
{
j = nextval[j];
}
if (T[i] == T[j + 1])
{
j++;
}
nextval[i] = j;
}
}这里计算的就是匹配串的前index(包括index)的字符串的最长前后缀相同的字符个数
例如:ababaaaba,那么
"a",next[1] = 0
"ab",next[2] = 0
"aba",next[3] = 1
"abab",next[4] = 2
"ababa",next[5] = 3
"ababaa",next[6] = 1
"ababaaa",next[7] = 1
"ababaaab",next[8] = 2
"ababaaaba",next[9] = 3
这个数组的作用就是,比如说:你在主串ababatabssss中匹配ababaaaba,你会发现前面5个字符都是一样的,就是第5+1个不一样
普通的匹配模式,主串会从第二个开始ababaaabssss,而匹配串从头开始ababaaaba
但是因为有next数组的存在,next[5]的存在,匹配串回到next[5]=3,然后主串位置不变,比较第3+1位
ababatabssss
abababaaaba
这样就可以减少很多的匹配次数了
KMP匹配算法主要是利用匹配失败后的信息来减少匹配的次数。
首先是先对匹配串的自我分析,也就是nextvalue数组的求解,里面求出的是下一个应该匹配的位置。
然后就可以将主串不断向后推移,匹配串不断选取合适的位置来和主串推移的位置进行比较。
//普通匹配查找串的位置
public int SimpleIndex(StringList T, int pos = 1) {
if (T.isEmpty() || this.isEmpty()) {
return 0;
}
int mainLength = this.Length();
int matchLength = T.Length();
int i;
if (pos > 0 && pos <= mainLength) {
i = pos;
while (i <= mainLength - matchLength + 1) {
StringList sub = this.SubString(i, matchLength);
if (sub.Compare(T) != 0)
{
i++;
}
else {
return i;
}
}
}
return 0;
}一步步截取匹配长度的子串和匹配串对比。并不效率!
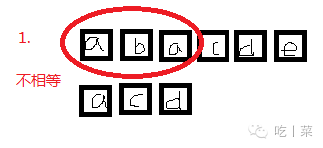
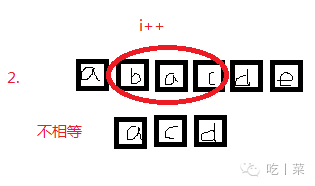
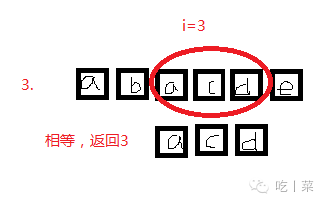
//比较两个串 1本串大 -1 s串大 0相等
public int Compare(StringList s) {
int sounceLength = this.Length();
int length = s.Length();
int i = 0;
int j = 0;
char c = '\0';
while (i < sounceLength && j < length) {
s.GetCharByIndex(j + 1, ref c);
if (this._data[i] > c) {
return 1;
}
if (this._data[i] < c) {
return -1;
}
i++;
j++;
}
if (sounceLength == length)
{
return 0;
}
if (sounceLength > length) {
return 1;
}
return -1;
}//获取子字符数组
private char[] subChar(char[] chars, int index, int length) {
if (chars == null) {
Console.WriteLine("截取的字符数组为空!");
return null;
}
int cLength = chars.Length;
if (length <1 || index < 1||index > cLength || index + length - 1 > cLength) {
Console.WriteLine("索引和长度错误!");
return null;
}
char[] newChar = new char[length];
for (int i = 0; i < length; i++) {
newChar[i] = chars[index - 1 + i];
}
return newChar;
}
//截取指定位置长度的串,成为一个新的串
public StringList SubString(int index, int length) {
char[] sub = this.subChar(this._data, index, length);
if (sub == null) {
return null;
}
StringList newString = new StringList(sub);
return newString;
}
//删除指定位置长度的字符串
public bool Delete(int index, int length) {
if (this.isEmpty()) {
Console.WriteLine("被删除的字符串为空!");
return false;
}
int sounceLength = this._data.Length;
if (index < 1 || index > sounceLength || length < 1 || index + length - 1 > sounceLength) {
Console.WriteLine("索引位置和长度错误!");
return false;
}
char[] term = this._data;
int newLength = sounceLength - length;
this._data = new char[newLength];
int go = 0;
for (int i = 0; i < newLength; i++) {
if (i == index - 1) {
go = length;
}
this._data[i] = term[i + go];
}
return true;
}①同样的需要判断串是否为空和索引的合法性
②临时保存原串的数据
③重构数据域大小为删除字符串后的长度
④遍历赋值,通过go位移跳过被删除的元素

//插入字符数组
public bool Insert(int index , char[] chars)
{
if (this.isEmpty()||chars == null) {
Console.WriteLine("插入的字符不能为空!");
return false;
}
int length = _data.Length;
if (index > length || index < 1) {
Console.WriteLine("索引位置错误!");
return false;
}
int cLength = chars.Length;
char[] term = _data;
_data = new char[length + cLength];
int i = 0;
for (; i < index - 1; i++) {
_data[i] = term[i];
}
for (int j = 0; j < cLength; j++) {
_data[i] = chars[j];
i++;
}
for (int k = index - 1; k < length; k++) {
_data[i] = term[k];
i++;
}
return true;
}①先判断本串和字符数组是否为空
②判断索引的合法性
③临时保存本串的数据
④重构本串的数据域大小为原串长度+插入字符数组长度
⑤原串index前的字符,插入的字符,原串index和其后的字符,分为三段分别按顺序赋值给新的数据域
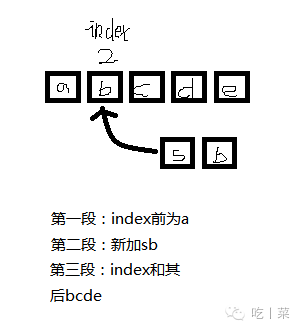
串其实解释我们平常用的string字符串,它也是一种线性表结构,不同的是,普通的线性表一般都是针对单个元素的,而串一般针对的是多个元素的操作。
//串的顺序存储结构
class StringList
{
private char[] _data;
public StringList(char[] chars) {
this.ValueTo(chars);
}
//创建空串
public StringList() {
this._data = null;
}
//串赋值为字符数组
public void ValueTo(char[] chars) {
if (chars == null) {
this._data = null;
return;
}
this._data = new char[chars.Length];
for (int i = 0; i < chars.Length; i++)
{
_data[i] = chars[i];
}
}
}可以看出,这里的串的数据域就是一个字符数组,数组的长度就是串的长度,因为c#的数组是可以重新定义大小的,所以分配到刚好的大小就好,也不用使用特殊符号来判定串的结束
有些语言的数组是不能重新定义大小的,所以扩大时会创建新的string(新的大小),缩小时以'\0'作为字符串的结束标志。
队列的链式存储结构很简单,需要两个变量指标来指向队头和队尾,这里的队尾是真实的队尾元素,用来添加元素。所以当队列只有一个元素时,队头和队尾指向的都是同一个元素。
分两种情况
①就是队尾rear指针大于队头指针front,length = rear - front
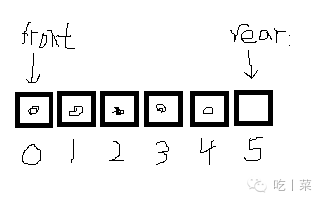
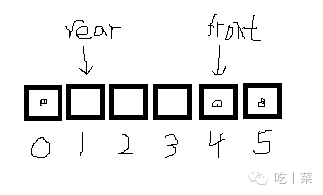
②队尾rear指针小于队头指针front
length1 = 数组长度 - front
length2 = rear
length = length1 + length2 = rear - front + 数组长度
③可以总结出
lenght = (rear - front + 数组长度)% 数组长度
//获取循环队列长度
public int GetLength() {
int maxLength = this._maxLength + 1;
return (this._rear - this._front + maxLength) % maxLength;
}